Virtual Memory (VM)
The VM subsystem of a processor allows each process to think that it owns the entire main memory. There aren't many restrictions on VM addresses. The VM address is translated to physical address by the MMU.
Note - The operating system fills in the page table data structures.
Apart from the translation of virtual to physical addresses, some systems offer an additional indirection i.e. segments. Segment limits have impact on performance on x86 systems.
Simple Address Translation
The MMU splits the virtual address into directory and offset. On x86 system a 32-bit virtual address is split into a 10-bit base address (directory) and 22-bit offset. The base address is used to refer to one of the page entries from the 1024 entries in the directory and the offset is used to refer to the entry in the page.
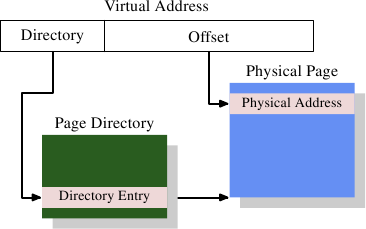
Note - The Page Directory data structure is populated by the OS and is stored in main memory. The OS stores the base address of this memory region in a special register.
On the x86 system the page directory contains 1024 page entries (2^10). Each entry points to the base address of a page, each of these pages is 4MB in size. The offset portion of the virtual address is 22 bits, to address every byte in the 4MB page.
Multi-Level Page Tables
Its beneficial to use smaller pages which can be aligned with memory pages. 4MB pages aren't efficient because of this reason. 4kB pages are the norm. Thus only 12 bits are needed for Offset. The remaining 20 bits are used for selecting the page entry, however 2^20 entries is not practical and thus multiple levels of page tables are used.
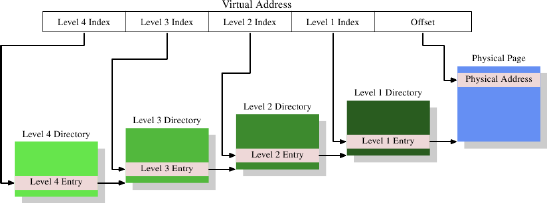
Page Tree Walking - the virtual address is broken down into multiple parts which act as indices in page directories. The last offset portion of virtual address is the offset in they page pointing to the physical address. This physical address isn't complete instead its the high part of the physical address, its completed by adding to it the page offset from the virtual address. x86 processor performs this walk in hardware, other processors need assistance from OS.
A small program could work with one entry at first three levels and 512 entries in the last level with 4kB physical pages allows it to address 2MB of memory. If the second last level also has 512 entries, the addressable memory increases to 1GB.
Note - Since stack and heap area of a process are allocated on opposite ends of the address space allowing them to grow as much as possible, the level 2 directory will contain at least two entries for this process.
Compilers offer address space randomization to reduce possible exposure to security exploits. This causes various sections of code, data, shared libraries to be loaded at random address, and thus there are multiple entries at each of the page table levels to bring in a larger address range. If performance is important this compiler flag should be turned off.
Note - The OS constructs these tables and when a new process is created or a table is changed, it notifies the processor.
Transition Look-Aside Buffer (TLB)
For every access via a virtual address, four memory accesses have to be made to determine the physical address. This can slow down the system, further these page tables are not cached in L1 or L2 caches as that would still be slow and if there is a cache miss the instruction pipeline would stall. The virtual to physical mapping is cached in the TLB, which is a small and fast cache.
Note - the offset portion of virtual address is simply added to the physical address stored in the last page i.e. the offset has no role in determining the physical address. The TLB contains the virtual to physical address mapping with the offsets stripped off. Thus multiple virtual addresses map to the same physical address prefix, consuming less space and a faster conversion.
If there is a TLB miss, the processor has to perform the costlier page table walk. TLBs are divided into instruction and data TLBs i.e. ITLB and DTLB. Further there are two levels of TLB caches, the L2TLB is usually unified as is the L2 cache. TLBs are specific to a processor at level 2, and specific to a core at level 1.
Todo - TLB entries can be prefetched by the hardware or the programmers can explicitly initiate it using prefetch instructions. Read more on prefetch instructions.
Each process has its own page table tree, but threads within a process share the same tree. If threads of the same process are executed on the same processor core, they can use the same TLB. If a page table for a process is changed or if the address space layout of a process changes then either -
- the TLB is flushed.
- the tags for the TLB entries are extended to uniquely identify the page table tree they refer to.
TLBs are flushed when a context switch causes a different thread or process to run, however the kernel address space is left in the TLB as the context switch requires kernel code to be executed.
Note - context switch to another thread of the same process also requires kernel code to execute in between, which will lead to TLB flush.
Though full TLB flushes are effective they are not efficient if the new process does not fill up the TLB and passes control back to the previously executing process, then the TLB has to be repopulated. For e.g. on a system call the user process is switched over to kernel code which does not require the entire TLB.
Todo - system calls execute in kernel context, but does it require a full context switch? Read more on this.
This expense can be avoided if TLB entries have an additional tag permitting partial flushes. This tag prevents flushing when the context switch is between threads of the same process. This is also useful when a Virtual Machine is running multiple OS's and the context switch is within the same OS.
TLB Performance & Page Size
A large page size implies that the virtual address would have a more bits in the offset portion compared to base address. Thus the small base address can be quickly mapped to a physical address by the TLB. However large page sizes aren't useful as most memory allocations would require memory to be page aligned for e.g. loading a executable would require page allocation and then not use all of the page space. Further, as memory allocations and deallocations happen, the memory will become fragmented and if multiple contiguous pages need to be allocated it may not be possible. Usually smaller page sizes of 4kB are preferred. Large page tables lead to smaller page trees, and thus if there is a TLB miss the cost of doing a page tree walk is small.
Linux allows allocating big pages at system start time using the special hugetlbfs filesystem. These large pages are reserved for exclusive use, where performance critical applications make use of them for e.g. database servers.
Note - read more about hugetlbfs.
Virtualization
Virtualization technologies involve a host operating system installed on the system and multiple guest operating systems running on top of it. The host sets up the page tables for the hardware and a separate page tree for each guest is setup and provided to the them. The guests use their page tree to allocate memory to the processes running on them. This separation of page tree's for each guest is known as guest domains.
Conversion of a virtual address for a process running on the guest OS, involves first converting to the virtual address of the host OS and then to the physical address on the hardware. Changes to the page tree by the guest OS are notified to the host OS which then updates its own page tree and notifies the hardware. These are expensive operations as there are multiple levels of abstraction.
Intel and AMD provide hardware support that allows converting guest virtual address to host virtual address in hardware. Intel's Extended Page Tables (EPT) and AMD's Nested Page Tables (NPT) speed up the address conversion process almost equivalent to the cost of no virtualization.
The TLB stores the complete translation from guest virtual address to physical address. AMD's Pacifica Extension and Intel's Virtual Processor ID are techniques to add information to each tag (for an entry in TLB) which allow grouping together TLB entries related to a process thus preventing them from getting flushed on a kernel context switch (as the guest process is expected to resume execution).
NUMA
Non-Uniform Memory Architectures are machine designs where multiple processors are connected to each other and to common main memory. In this case there are multiple processors (each processor with multiple cores) connected to the northbridge which links them to the main memory. Its possible that a processor is not directly linked to every other processor i.e. the connection between two processors may involve going through an intermediate processor.
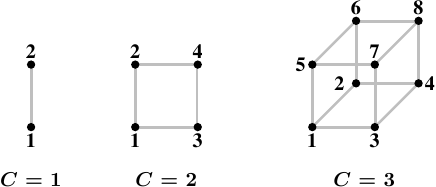
Processors can access their local memory with the lowest latency, followed by memory of their immediate neighbors and so on. This access time is known as NUMA Factor.

The operating system ensures that memory allocated to a process is from the main memory local to the processor. Shared libraries are loaded once for all processes that refer to it on a processor, however if multiple processes running on different processor refer to a shared library its optimal to load it multiple times i.e. once for each processor. Migrating processes from one processor to another will require that the memory referenced by the process is also transferred, thus OS scheduling needs to account for this.
Linux Kernel and NUMA
The sysfs file system provides information related to NUMA.
- /sys/devices/system/node/node* - node0, node1 and so on are the number of NUMA nodes or sockets/cpu/processors.
- /sys/devices/system/node/node0/cpulist - lists the cores with their id's on each node.
- numactl --show and numactl --hardware - list relevant information on nodes and cpus.
- /sys/devices/system/cpu/cpu*/ - another useful directory containing information on each core.
- /sys/devices/system/node/node*/distance - contains the numa factor for the node when accessing information in other nodes.
The VM subsystem of a processor allows each process to think that it owns the entire main memory. There aren't many restrictions on VM addresses. The VM address is translated to physical address by the MMU.
Note - The operating system fills in the page table data structures.
Apart from the translation of virtual to physical addresses, some systems offer an additional indirection i.e. segments. Segment limits have impact on performance on x86 systems.
Simple Address Translation
The MMU splits the virtual address into directory and offset. On x86 system a 32-bit virtual address is split into a 10-bit base address (directory) and 22-bit offset. The base address is used to refer to one of the page entries from the 1024 entries in the directory and the offset is used to refer to the entry in the page.
source lwn.net
Note - The Page Directory data structure is populated by the OS and is stored in main memory. The OS stores the base address of this memory region in a special register.
On the x86 system the page directory contains 1024 page entries (2^10). Each entry points to the base address of a page, each of these pages is 4MB in size. The offset portion of the virtual address is 22 bits, to address every byte in the 4MB page.
Multi-Level Page Tables
Its beneficial to use smaller pages which can be aligned with memory pages. 4MB pages aren't efficient because of this reason. 4kB pages are the norm. Thus only 12 bits are needed for Offset. The remaining 20 bits are used for selecting the page entry, however 2^20 entries is not practical and thus multiple levels of page tables are used.
source lwn.net
Page Tree Walking - the virtual address is broken down into multiple parts which act as indices in page directories. The last offset portion of virtual address is the offset in they page pointing to the physical address. This physical address isn't complete instead its the high part of the physical address, its completed by adding to it the page offset from the virtual address. x86 processor performs this walk in hardware, other processors need assistance from OS.
A small program could work with one entry at first three levels and 512 entries in the last level with 4kB physical pages allows it to address 2MB of memory. If the second last level also has 512 entries, the addressable memory increases to 1GB.
Note - Since stack and heap area of a process are allocated on opposite ends of the address space allowing them to grow as much as possible, the level 2 directory will contain at least two entries for this process.
Compilers offer address space randomization to reduce possible exposure to security exploits. This causes various sections of code, data, shared libraries to be loaded at random address, and thus there are multiple entries at each of the page table levels to bring in a larger address range. If performance is important this compiler flag should be turned off.
Note - The OS constructs these tables and when a new process is created or a table is changed, it notifies the processor.
Transition Look-Aside Buffer (TLB)
For every access via a virtual address, four memory accesses have to be made to determine the physical address. This can slow down the system, further these page tables are not cached in L1 or L2 caches as that would still be slow and if there is a cache miss the instruction pipeline would stall. The virtual to physical mapping is cached in the TLB, which is a small and fast cache.
Note - the offset portion of virtual address is simply added to the physical address stored in the last page i.e. the offset has no role in determining the physical address. The TLB contains the virtual to physical address mapping with the offsets stripped off. Thus multiple virtual addresses map to the same physical address prefix, consuming less space and a faster conversion.
If there is a TLB miss, the processor has to perform the costlier page table walk. TLBs are divided into instruction and data TLBs i.e. ITLB and DTLB. Further there are two levels of TLB caches, the L2TLB is usually unified as is the L2 cache. TLBs are specific to a processor at level 2, and specific to a core at level 1.
Todo - TLB entries can be prefetched by the hardware or the programmers can explicitly initiate it using prefetch instructions. Read more on prefetch instructions.
Each process has its own page table tree, but threads within a process share the same tree. If threads of the same process are executed on the same processor core, they can use the same TLB. If a page table for a process is changed or if the address space layout of a process changes then either -
- the TLB is flushed.
- the tags for the TLB entries are extended to uniquely identify the page table tree they refer to.
TLBs are flushed when a context switch causes a different thread or process to run, however the kernel address space is left in the TLB as the context switch requires kernel code to be executed.
Note - context switch to another thread of the same process also requires kernel code to execute in between, which will lead to TLB flush.
Though full TLB flushes are effective they are not efficient if the new process does not fill up the TLB and passes control back to the previously executing process, then the TLB has to be repopulated. For e.g. on a system call the user process is switched over to kernel code which does not require the entire TLB.
Todo - system calls execute in kernel context, but does it require a full context switch? Read more on this.
This expense can be avoided if TLB entries have an additional tag permitting partial flushes. This tag prevents flushing when the context switch is between threads of the same process. This is also useful when a Virtual Machine is running multiple OS's and the context switch is within the same OS.
TLB Performance & Page Size
A large page size implies that the virtual address would have a more bits in the offset portion compared to base address. Thus the small base address can be quickly mapped to a physical address by the TLB. However large page sizes aren't useful as most memory allocations would require memory to be page aligned for e.g. loading a executable would require page allocation and then not use all of the page space. Further, as memory allocations and deallocations happen, the memory will become fragmented and if multiple contiguous pages need to be allocated it may not be possible. Usually smaller page sizes of 4kB are preferred. Large page tables lead to smaller page trees, and thus if there is a TLB miss the cost of doing a page tree walk is small.
Linux allows allocating big pages at system start time using the special hugetlbfs filesystem. These large pages are reserved for exclusive use, where performance critical applications make use of them for e.g. database servers.
Note - read more about hugetlbfs.
Virtualization
Virtualization technologies involve a host operating system installed on the system and multiple guest operating systems running on top of it. The host sets up the page tables for the hardware and a separate page tree for each guest is setup and provided to the them. The guests use their page tree to allocate memory to the processes running on them. This separation of page tree's for each guest is known as guest domains.
Conversion of a virtual address for a process running on the guest OS, involves first converting to the virtual address of the host OS and then to the physical address on the hardware. Changes to the page tree by the guest OS are notified to the host OS which then updates its own page tree and notifies the hardware. These are expensive operations as there are multiple levels of abstraction.
Intel and AMD provide hardware support that allows converting guest virtual address to host virtual address in hardware. Intel's Extended Page Tables (EPT) and AMD's Nested Page Tables (NPT) speed up the address conversion process almost equivalent to the cost of no virtualization.
The TLB stores the complete translation from guest virtual address to physical address. AMD's Pacifica Extension and Intel's Virtual Processor ID are techniques to add information to each tag (for an entry in TLB) which allow grouping together TLB entries related to a process thus preventing them from getting flushed on a kernel context switch (as the guest process is expected to resume execution).
NUMA
Non-Uniform Memory Architectures are machine designs where multiple processors are connected to each other and to common main memory. In this case there are multiple processors (each processor with multiple cores) connected to the northbridge which links them to the main memory. Its possible that a processor is not directly linked to every other processor i.e. the connection between two processors may involve going through an intermediate processor.
source lwn.net
Processors can access their local memory with the lowest latency, followed by memory of their immediate neighbors and so on. This access time is known as NUMA Factor.
source http://cs.nyu.edu/~lerner/spring10/projects/NUMA.pdf
Linux Kernel and NUMA
The sysfs file system provides information related to NUMA.
- /sys/devices/system/node/node* - node0, node1 and so on are the number of NUMA nodes or sockets/cpu/processors.
- /sys/devices/system/node/node0/cpulist - lists the cores with their id's on each node.
- numactl --show and numactl --hardware - list relevant information on nodes and cpus.
- /sys/devices/system/cpu/cpu*/ - another useful directory containing information on each core.
- /sys/devices/system/node/node*/distance - contains the numa factor for the node when accessing information in other nodes.